长期记忆系统
反思
- 元提示(框架):
- 向 llm 提问,让其回顾失败,生成摘要避免未来犯错
观察
- 原始日志收集
- 合成日志
- 让 llm 总结出新洞察
选择
- 工具集
- 使用 RAG 建立工具索引,这样子可以把最相关的 n 个加载进上下文而无需全部加载
- 固定+遮蔽:
- 通过复用 cv 缓存来加速
- 混合检索
- 多路召回:向量、关键词、知识图谱,多方面去获取信息
- Agentic 探索: agent 在循环中,主动使用检索工具进行多步推理
- 重排序:把召回的数据进行二次总结,用更加精细的规则或模型去提高信噪比
压缩
- 上下文总结
- LLM 提炼
- 总结对话历史(提炼成任务概览)
- 对海量的 API 返回结果总结成摘要
- LLM 提炼
- 上下文裁剪
- 丢弃信息
- 滑动窗口(只保留最近n轮对话)
- 用轻量级的模型进行智能裁剪
- 丢弃信息
微调 vs 上下文工程
- Manus 团队优先上下文工程发展
kv 缓存设计
- kv 缓存工作机制
- 前缀匹配
- 提高缓存命中率的工程原则
- 选用 vllm 这种能支持 kv 缓存功能的现代推理框架
- 缓存只存于同一个推理进程,所以需要用唯一标识来确保同一个会话请求打到同一个进程
- 保持前缀稳定
- 上下文只追加,不修改或删除中间部分
- 如果不支持自动前缀匹配的框架,需要手动插入断电来进行缓存
工具选择
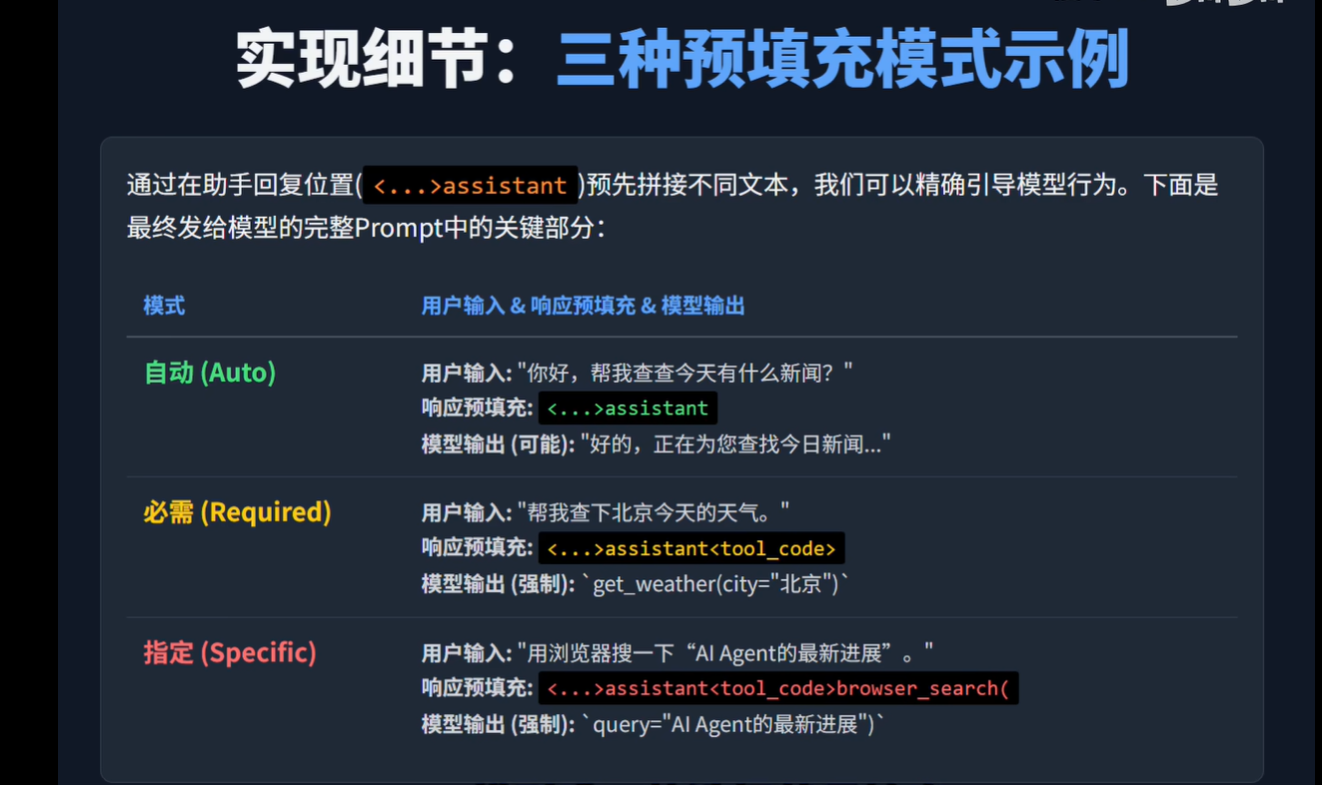
响应预填充
通过特定的前缀标签,为模型提前提供模式信号,引导他提前激活相应的模式
专注力
todo.md
- 通过 write 工具在两个关键时机更新 todo.md
- 复杂任务分解后写入
- 完成每个子任务就覆写最新进度
反直觉
将错误日志保留在上下文中,降低其重复犯错可能
多 Agent 协作
- 通信
- 上下文不共享,子 agent 只处理原子性子任务
- 共享上下文
- 类似于 fork
- 子 agent 拥有主 agent 全部历史+子 agent 新 system prompt
三层工具
- 极少数、固定的原子函数
- 能力扩展,通过第一层的原子函数(execute_shell)调用获得外部动态工具箱
- 组合使用第一层和第二层编写并执行脚本
处理大型工具输出
- 创建子 agent 去提炼,只返回固定的、结构化的结果。(就是一层层套娃,直到套娃到原子行为)